前回の記事で、楽天市場のスクレイピングの基本を紹介しました。
今回は、それを少しステップアップして、機能を付け足して行きたいと思います。
目次
追加する機能
今回追加する機能や改善する部分は以下の2点です。
1 複数のキーワードに対応
まず、前回は「コーヒー」という単一のキーワードをプログラム内に埋め込んでいました。
これだと、常に1個のキーワードしか結果を表示出来ません。
「コーヒー」の他に「ラーメン」というキーワードも定期的に結果を見たい。というニーズがあった場合に、いちいち「ラーメン」に書き換え、また「コーヒー」に戻す。
こんな作業が必要になります。
面倒くさいですよね。
ということで、複数のキーワードを同時に調査できるような仕組みにしていきます。
2 検索結果の表示を見やすく
前回は、単純に商品名を羅列しただけでしたので、非常にそっけない表示でした。
これにもう少し情報を付け加えたり体裁を整えたりして、読みやすい結果画面にしたいと思います。
完成コード
では、完成形をまずは書いておきます。
import requests from bs4 import BeautifulSoup kws=[] kws.append('コーヒー') kws.append('ラーメン') for kw in kws: url='https://search.rakuten.co.jp/search/mall/'+kw+'/' html=requests.get(url) soup=BeautifulSoup(html.text,'html.parser') items=soup.select('.searchresultitem .title') rank=1 for item in items: print('キーワード:{} 順位:{}'.format(kw,rank)) print('商品名:{}'.format(item.text).replace('\n','')) print('*/'*20) rank+=1こんな感じです。
前回の9行プログラムに比べると、スペース行を除いて16行ありますので約2倍の量のプログラムになりました。
でもまだまだ少ないですよね。実行結果
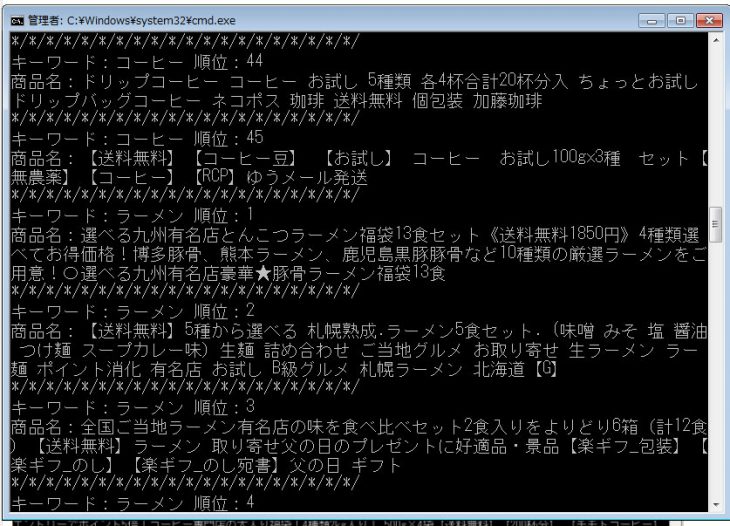
では、このプログラムを実行した結果画面を見てみましょう。
こんな感じです。
前回作った画面とそれほど大きくは変化していませんが、細かいところを少し変えて、見やすさをアップさせました。
- 各商品名の前に、キーワードと順位を表示させた
- 商品名に不要な改行が含まれていたのを削除した
- 各商品名のあとに、区切り文字「*/*/*/*・・・・」を入れ、見やすくした
という点を変更しました。
解説
では今回も1行ずつ見ていきましょう。
前回習った部分はスルーしますので、必要に応じて前回の記事も参考にしてくださいね。文字コード・モジュールの宣言
1行目から3行目は前回と全く同じです。
プログラムの文字コード宣言と、必要なモジュールの読み込みを行います。
リストの定義
kws=[]
今回、新しい概念として複数キーワードというものがあります。
沢山の調査対象キーワードを事前に羅列しておけば、それを順次検索し、結果を取得してくれるわけですね。まず、kwsという名前は、「keywords」を短縮してkwsという名前にしていますが、なんでも良いです。
kwsは、通常の変数ではなく、pythonのリスト型になっています。
リスト型とは、複数のデータ(棚)を格納できる「タンス」のような概念ですね。
kws=[]という感じで、中身のない中括弧を代入すれば、「kwsというのはリスト型なんだよ」ということをpythonに伝えることが出来、以後のプログラムではkwsという文字をリストとしてみなしてくれます。この宣言をしないと次の行以降でエラーが出ますので、リストを使うときは宣言を忘れないようにしてください。
リストへのキーワード格納
kws.append(‘コーヒー’)
kws.append(‘ラーメン’)ここでは、↑で宣言した「kws」というリストに、実際のデータを入れています。
リスト型は、どんどんデータを追加していくことが出来ます。
具体的に、「リスト名.append(追加したいデータ)」という形式でappendという関数を利用してデータを追加していくことになります。リストは、中括弧に添字を書くことで、参照したり変更するデータを指定できます。
例えば、kws[0] は、「コーヒー」ですし、kws[1]は「ラーメン」という文字列がここで入ることになります。
ここで、pythonの添字は 0からはじまることに注意してください。では、更に「ワイン」を足したいときはどうすればよいでしょうか。
もうおわかりですよね。
kws.append(‘ワイン’)
という文を更に追加するだけです。
appendというのは「追加」という意味ですので、そのままですね。kwsリストにワインを追加する、という意味です。このように、リスト型は、一つのリスト名「kws」というものに、どんどんデータを格納することができる便利な型となります。
これで、kwsリストには、コーヒーとラーメン の2つのデータが準備されたことになります。
すべてのキーワードを回す
for kw in kws:
これは何をしているかというと、設定したkwsリストの中身を一つずつ読み出し、リストの最後に達するまで繰り返す という文です。
kwsには2つのデータが入っていますので、このfor文は、
1回目にはkws[0]の「コーヒー」がkw変数に代入される。
2回目にはkws[1]の「ラーメン」がkw変数に代入される。
というのを自動で行ってくれます。ポイントは、kwsリストに何個データが入ってようと、そのデータがある限り、最後のデータに達するまで自動で何度でも繰り返してくれることですね。
urlを作成する
前回は、コーヒーで検索する というURLをズバリ設定していましたが、今回は複数のキーワードに対応するため、それぞれのキーワードのURLを都度自動で設定していくと便利です。
url=’https://search.rakuten.co.jp/search/mall/’+kw+’/’
ここでは、「https://search.rakuten.co.jp/search/mall/」という共通部分の後に、自動でキーワードを入れてある変数kwの内容を付け加え、最後に「/」を付け加えています。
文字列をつなげてurlという変数に入れているわけですが、pythonでは文字列の連結は、「+」という記号を使います。
普通は「+」記号は数字同士を足す計算式に使われますが、pythonでは文字列で使うと単純に文字列を結合してくれます。
「’しょうゆ’+’ラーメン’」だと「’しょうゆラーメン’」になる というイメージです。ここでkwsリストから取り出してきたkwを含んだURLを作ることが出来ました。
サイトからHTMLを取得し、解析
html=requests.get(url)
soup=BeautifulSoup(html.text,’html.parser’)
items=soup.select(‘.searchresultitem .title’)この部分は前回と全く同じです。
urlのwebページにアクセスし、その結果のページHTML文を解析しsoup変数に入れる。
その後、soupに入っているHTMLから「.searchresultitem .title’」のcssセレクタに該当する部分のみをitemsというリストに格納する。ということをしています。
順位の変数を初期化
rank=1
今回は、順位の数字を表示するように変更しています。
ですので、そのデータを設定する必要があります。順位は1から2・3・4・・・と1つずつ増えていく数値ですので、まずは最初の順位「1」をrank変数に代入しています。
もちろん、コーヒー の後の ラーメン に変更したときに、順位がそのまま続いてしまうと、ラーメンの1位が46位と表示されてしまうので、for文でkwsからキーワードを読み込んだ時点でrank変数を1に初期化しています。
商品名を取り出し、整形して表示する
for item in items:
print(‘キーワード:{} 順位:{}’.format(kw,rank))
print(‘商品名:{}’.format(item.text).replace(‘\n’,”))
print(‘*/’*20)
rank+=1この部分は、各順位の商品の情報を次々に読み込み、画面に表示をする部分です。
前回と最初の「for item in items:」の部分は同じですので、そこは省きます。まずは「print(‘キーワード:{} 順位:{}’.format(kw,rank))」の部分ですが、前回もやったprint文です。
少し違うのは、文中に「{}」という波括弧がいくつか入っているのと、「format」という関数が使われている点です。
次で説明をします。format命令
ここで使っているformat命令文は、ある文字列中に変数を入れ込むのによく使います。
非常に便利な関数ですので覚えてくださいね。例えば、「私の名前は山田太郎です」 と表示させる場合、「山田」というsei変数と「太郎」とうmei変数を表示させる場合、
print(‘私の名前は{} {}です’.format(sei,mei))という文を書けば、1つ目の波括弧{}には、format()で指定した一つ目の変数「sei」が入り、
2つ目の波括弧{}には、format()で指定した2つ目の変数「mei」が自動で入ることになります。
変数はカンマで区切るようにしてください。単に「私の名前は山田太郎です」という文を書きたいだけなら
print(‘私の名前は山田太郎です’)
と書いた方が早いですが、今回はfor文の中でどんどん中身を変えながら順位やキーワード、商品名を表示しています。そういうときにこのformat関数とリストや変数を使うと1つの命令で、何度も違う文字列を表示できて便利です。
今回は、まずキーワード と順位 を表示させ、次のprint文で、商品名を表示させています。
区切り線を入れる
print(‘*/’*20)
という部分を説明します。
これは「*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/*/」という、順位ごとの区切りを見やすくするために表示する区切り線です。
「*/」という一つのパーツを’*/’*20 という形で20回掛けていますので、20回勝手に繰り返して表示されます。こういう細かい部分でプログラムを短く、見やすくできるのがpythonのニクい所ですね。
順位数を増やす
rank+=1
最後に、この部分です。
これは、順位数をあらわす「rank」という変数を1増やしています。
1つの商品名の表示が完了したら、次の順位の表示に移るため、ここでrankを増加させています。
こういう処理のことをプログラミングでは「インクリメント」と言います。rank=rank+1 という書き方でも良いですし、 rankに1を足した数値をrankに入れてください。という意味で
rank+=1 という短縮形で書くことも出来ます。ちょっとプロっぽい書き方ですが、プログラムを短くわかりやすくするテクニックでもあるので、是非この書き方は覚えてください。
まとめ
以上で、今回のpython講座は終わりです。
複数のキーワードに対応したことで、かなり実用的なプログラムになってきました。
また、表示を整えることで、ユーザがデータを利用しやすく、理解しやすくなって来たと思います。こうやって、ひとつずつ機能強化をしながら、最終的に大きなサービスやシステムを作っていけるのがプログラミングの醍醐味ですよね。
では、次の講座もお楽しみに!
クジラ飛行机 ソシム 2016-12-06