今回は、たった9行のコードで楽天市場の検索結果から商品名を自動で抜き出すことが出来るというプログラミングの内容です。
初心者でもとっつきやすいよう、機能を絞った最小のプログラムになりますが、Pythonの楽しさや、スクレイピングの楽しさを実感していただきたいと思い、記事にしました。
でははじめ!
目次
想定の対象者
他のプログラミング言語より比較的に簡単なPythonですが、各コードの意味を理解しようとすると、ある程度のプログラミングの基礎知識や多言語での経験が必要です。
オブジェクト思考の考え方も知っていると、より良いです。
とはいえ、初学者でもなるべく理解できるような説明もしていきますね。
何をしたいか
今回実現したいことをまず書いておきます。
楽天市場の検索結果をスクレイピングして、情報を収集する
ということを実践して行きたいと思います。
いきなり色々な機能を付けると複雑になってしまうので、最小のコードで、スクレイピングの楽しさを感じていただけるようなプログラムから始めていきましょう。
まずは、楽天市場の検索で「コーヒー」と入力した検索結果の1ページ目の検索結果を取得し、その商品名を全部表示する というプログラムにします。
コード
まずは、完成形のコードを書いておきます。
# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup url="https://search.rakuten.co.jp/search/mall/コーヒー/" html=requests.get(url) soup=BeautifulSoup(html.text,'html.parser') items=soup.select('.searchresultitem .title') for item in items: print(item.text)これだけです。
たった9行です。
思ったより少ない量ではないでしょうか。この少ないコードで実現できるのがPythonの強みです。
実行結果
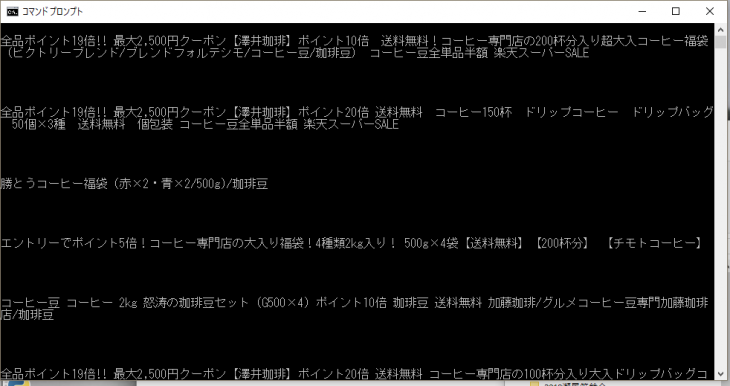
このプログラムコードを実行すると、↓のような商品名がずら~ーっと単純に羅列したものが表示されます。
普段のWindowsやmacの画面に慣れていると、なんともつまらくて殺風景に見えることでしょう。僕はWindows3.1+MS-DOSの頃からPCに触れていますので、ギリギリこの黒画面にも抵抗はない世代です^^;
解説
では、1行ずつ何をしているかを説明しましょう。
1行目:文字コードの宣言
1行目
# -*- coding: utf-8 -*-
とあります。
これは、このPythonファイルの文字コードを明言するためのおまじないです。
Pythonは標準でUTF-8という、現在主流の文字コードを使いますが、念の為コードの1行目か2行目 つまり先頭で「このファイルはUTF-8で書いてありますよ」ということを宣言してあげることになっています。
よほどのことがない限り、これを別の文字コードに変更することはないと思いますので、これはもうルーチンとして必ず先頭に書く というクセをつけておきましょう。
2-3行目:必要なモジュールを読み込む
2行目・3行目を見てみましょう。
from bs4 import BeautifulSoup
import requestsとなっています。
この2行は少し文法が違いますが、同じような意味のコードで、モジュールの組み込みを行うコードです。
モジュールとは
Pythonにはモジュールという概念があり、もともとPythonが標準的に持っている機能に付け加えて、世界中のプログラマーが作成した外部プログラムを部品のように組み込む事ができます。
すると、Pythonは標準で出来ることだけでなく、出来ることがどんどん増えていきます。
自動車を買うときに、いろいろメーカーのオプションを付けていくような感覚で、自分の作るプログラムに、必要な機能だけ組み込むことができるのです。これにより全部の機能を自分でプログラミングしなくても、誰かが作った機能を簡単に使うことが出来るのです。
Pythonはこのモジュールやライブラリと言われる便利な部品が山のようにあり、これがPythonの価値を高めています。
import requests
2行目の「import requests」は、import文といい、外部のモジュールを読み込む命令文です。
「requests」というモジュールは、インターネット上のデータを取得してくる場合にWEBと通信してくれる機能を持っています。
このモジュールを読み込むことで、今回スクレイピングする楽天市場のサイトのHTMLを取得してPythonで扱うことが出来るわけですね。
from bs4 import BeautifulSoup
3行目「from bs4 import BeautifulSoup」は、2行目と同じく外部のモジュールを使うことを宣言するコードです。
2行目と違うのは、from句が付け足されています。
2行目ではrequestsというモジュールを読み込み、その中に含まれる部品(関数)を全部使うことができます。3行目は、bs4というモジュールから、BeautifulSoupという部品を読み出す命令です。
「bs4」というモジュールの中の「BeautifulSoup」という一部の部品(関数)のみ読み込む場合に、このようなfrom A import B
という書き方をします。
Aの部分には、読み込むモジュール名を書きます。
ここでは「bs4」というモジュールを指定しています。今回は、bs4というモジュールに含まれる「BeautifulSoup」という部品のみ読み込むということを明言しています。
これにより、PythonはBeautifulSoupというクラスを使うことが出来るわけです。
4行目:スクレイピングするURLを設定する
次に4行目を見ましょう。
url=”https://search.rakuten.co.jp/search/mall/コーヒー/”
何をしている文?
この文は、urlという変数に、これからアクセスして情報を取得するURLを入れています。
楽天市場の検索の仕組みは、https://search.rakuten.co.jp/search/mall/ という定形のもののあとに、検索したいキーワードを続けることで、その検索結果を取得することができます。
まずは、「コーヒー」という検索キーワードを予め指定したURLをそのままurlという変数に入れておくこととしましょう。
変数に入れることで、次から「https://search.rakuten.co.jp/search/mall/コーヒー/」と長いアドレスを書くことなく、「url」という簡略化した名前(変数名)でアクセスすることができます。
5行目:WEBにアクセスして、結果のページデータを取得する
5行目を見てみましょう。
html=requests.get(url)
とあります。
先ほど設定したurlというアドレスにアクセスして、その検索結果のページデータをhtmlという変数に入れてください。という文です。
requests.getとは
プログラムに慣れて居ない方はここで躓きがちですが、この文では先程2行目で読み込んだモジュール「requests」の機能を使っています。
requestsというモジュールに含まれるgetという関数に対して、4行目で説明したurlというアドレスを指定しています。
これにより、Pythonが勝手に楽天市場にアクセスをして、その結果のデータを取得してくれます。これで、htmlという変数には、無事楽天市場の検索結果のHTML文章が格納されました。
6行目:BeautifulSoupでHTMLを扱いやすいデータ形式にする
6行目を見てみましょう。
soup=BeautifulSoup(html.text,’html.parser’)
とあります。
3行目で読み込んだ外部モジュールbs4のBeautifulSoupクラスを使って、5行目で変数htmlに格納したHTMLデータを、プログラムで取り扱いやすい形式に解析・変換してくれます。
BeautifulSoupの構文
BeautifulSoupというクラスに対して、まずhtml.textを渡します。
html は5行目で読み込んだ検索結果のHTMLのオブジェクトですが、そのHTML文を指定するときにhtml.textと表現します。次に、「html.parser」の部分は、HTML文の解析をするときに、Pythonに標準で用意されているhtml.parserという解析システムを使いますよ、という部分になります。
こういう解析システムは、「パーサー」と呼ばれます。
パーサーには他にもいろいろありますが、ここではPython標準のhtml.parserを使います。解析・構造化されたデータが出来る
以上で解析され、扱いやすいように構造化されたデータが「soup」という変数に格納されました。
次から、このsoupの中身から、必要な検索結果の商品名を取り出していくこととなります。
7行目:HTML文の中から、商品名の部分だけを抜き出す
7行目を見ましょう。
items=soup.select(‘.searchresultitem .title’)
これは6行目で準備したsoupというデータの中から、指定したCSSセレクタに該当するHTML部分のみ「items」という変数に入れてください。
という文です。CSSセレクタで商品名の部分だけ抜き出す
HTML文には、いろんなタグ(DIVとかIMGとか)が含まれますが、それぞれのタグには名前が付いています。
楽天のHTML構造で言えば、検索結果の商品の1つ1つが「searchresultitem」 というcssクラス名の付いたDIVタグで包まれています。
さらにその中に商品名を示す「.title」という部品を必ず持っていますので、それを指定します。select(CSSセレクタ) という命令で、必要な部分のみ抜き出すことができます。
この書き方は、CSSファイルを書いたことがある人ならすぐわかると思いますが、一般的なCSSのセレクタ構文がほぼそのまま使えますので、簡単に必要な部分だけを指定することが出来てとても便利です。items変数は、リスト形式
.searchresultitem .title で指定した商品名は、1つの検索結果ページに45個含まれています。
つまり、今回の文で得られる結果は、45個あるわけです。それをitemsという1つの変数に格納してくれるわけですが、Pythonはリストという仕組みがあり、複数の変数を一つのitemsというリストに入れられます。
ここでは45個の商品名をitemsリストに格納してくれたことになります。これで、目的の検索結果の商品名の準備がすべて完了しました。
8-9行目:商品名を表示する
最後の命令文です。
今までの文で準備した商品名を画面に表示しましょう。それが8行目・9行目です。
for item in items:
print(item.text)ここでは、for というPythonの基本構文を使います。
8行目では、さきほど45個の商品名を格納したリスト「items」に対して1個目から45個目まで、1つづつ取り出し、itemという変数に次々に格納してくれます。
for文は1回の命令で次々に沢山のデータに対して同じ処理をすることが出来ます。
画面表示
9行目は、8行目でitemに次々に格納される商品名を、順次画面に表示するというprint というPythonの基本命令を使います。
print(表示したい変数や値)
という書き方で、画面に表示がされます。ここでは、itemで格納された商品名のHTML文の中から、テキスト部分 つまり商品名そのもの を表示するという文ですね。
実は、最短4行で実現できます
今回のプログラムは、見通しの良さと理解のしやすさを考慮して、やや丁寧なコードにしました。
ですが、最短で書こうと思えば、4行で実現できてしまいます。
import requests from bs4 import BeautifulSoup for item in BeautifulSoup(requests.get("https://search.rakuten.co.jp/search/mall/コーヒー/").text,'html.parser').select('.searchresultitem .title'): print(item.text)こんな感じ。
各段階で変数に値を代入していたのを、全部省いてしまえば こういう超短いコードで書いてしまうことも可能です。
ですが見にくくなりますし、第三者が見たらわかりにくいことこの上ないのでおすすめはしませんが、Pythonの可能性は感じていただけると思います。
まとめ
この9行のコードを実行すれば、画面に45商品分の商品名が次々に表示がされると思います。
ちょっと感動じゃないですか?普通ならブラウザを立ち上げ、楽天市場のサイトに行って、「コーヒー」と入力して検索ボタンを押し、その結果ページの商品名を一個一個コピペしていくような作業が必要になるところが、この9行のプログラムだけですべて自動で商品名を抜き出せるわけです。
手動でやったら余裕で5分以上はかかる作業ですが、それがプログラムを呼び出すだけで2−3秒で出来てしまいます。
このようなスクレイピングは、楽天市場だけではなく、どのサイトにも有効です。
今回は、基本のスクレイピングプログラムをかなり丁寧に見てみました。
次からは、このプログラムを拡張していき、どんどん機能を増やしていければ良いと思います。クジラ飛行机 ソシム 2016-12-06